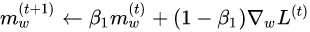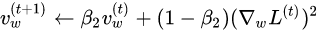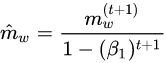Wet/Dry Cough Analysis and Differentiation


Introduction
One symptom that often accompanies an illness is a cough. It has been noted that certain types of coughs are often associated with certain medical conditions. This relationship has led to the practice using coughs to aid in the diagnosage of patients. For this study, we will attempt to differentiate between two common cough categories, Wet and Dry coughs.
A Wet cough is caused by the presence of mucus in the airway. The common causes of a wet cough include cold,flu, pneumonia,chronic obstructive pulmonary disease (COPD), emphysema,chronic bronchitis,acute bronchitis or asthma
A Dry cough is a cough where mucus is not present in the airway. Dry coughs may occur in long fits and are often caused by irritation in the respiratory tract. The common causes of dry coughs include flu, cold, laryngitis, sore throat, croup, tonsillitis, sinusitis, asthma, allergies, or exposure to irritants such as air pollution, dust, mold, or smoke
Background Research
Before analysis began a limited background search was performed. Survey papers in the area of auscultation were consulted to give a general understanding of the current standing of the field and to discover methods to analyze the data. The survey papers listed several methods common within the field including FFT, Spectral Contrast, and MFCC.3 Several papers mentioned additional techniques often applied to music identification such as Chromagraph and Tonnez as possibly relevant to auscultation research. These techniques will be presented in more detail in the Feature Extraction Section. Additional research on the differences between a dry and wet cough and previous wet/dry cough studies were also consulted.
Data Collection
Cough Collection 1
The initial data collection known henceforth as Cough Collection 1 consisted of 24 samples collected in a clinical setting by several doctors volunteering their time. The collection is a mix of wet and dry coughs from both female and male patients. The coughs were recorded in either WAV sampled at 16000 Hz or MP4a sampled at 48000Hz by cell phone applications. Each recording contains multiple coughs. The filename of each cough included a substring denoting gender and cough type. E.g FWC = Female wet cough, MDC = Male dry cough.
Cough Collection 2
After a preliminary analysis was performed on Cough Collection 1 several doctors from UMDNJ deemed the preliminary analysis sufficient to begin a second data collection. The second data collection will be referred to as Cough Collection 2 going forward. The preliminary analysis is presented in a later section of this document. Cough Collection 2 is ongoing and is expected to produce 100 samples. Coughs were collected by a doctor in a clinical setting from both Male and Female patients. Each recording contains multiple coughs. The collection consists of cough recording saved in OPUS format with a sampling rate of 16000 Hz. The file names were changed to reflect the gender and cough type while also matching the file naming convention developed during Cough Collection 1 except files from Cough Collection 2 begin numbering from 200. E.g FWC200, FWC201, MDC200,MWC200. The OPUS files were converted to wav files with a sampling rate of 16000Hz. An excel log was kept to track cough samples as they came in.
Visualizing the Data
Before any analysis was conducted, the data was visualized to gain an understanding of the structure of the data and to perform quality checks.

Data Standardization (Pre processing )

Cough Collections 1 & 2 contained files with differing naming conventions several different audio formats. These inconsistencies were rectified during the standardization process. The file names were renamed into a standardized format of ( Gender Type of Cough Number .extension).
Where:
- Gender = M/F
- Type of Cough = WC/DC
- Number = linearly increasing number.
Example:
- Original Filename = S1.3MDC2.wav
- ` New File name = MDC1.wav
All the files were converted into 16KHZ Mono Wave and the average amplitude of each cough sample was set to -20 db. This amplitude normalization step was required to correctly segment the coughs into individual coughs.
A log was produced that includes the original file name, new file name, and if file conversion was required for a given cough sample.
Segmenting the audio files into separate coughs
Each audio file from Cough collections 1&2 contains multiple coughs. Due to the large number of samples expected, 124 files between Cough Collections 1&2, manual separation was deemed to be untenable. An audio segmenter was written to split each audio file into individual coughs. All audio files were previously set to the same average amplitude level (-20dB) during the standardization step. The files were split where the audio exceeds a threshold. The threshold was determined experimentally.
Full audio file

Audio segment

This method works reasonably well but problems do arise such as segments containing silence, blips, or human voices are sometimes generated. To correct this issue of generating silence and quick blip segments the entire dataset( Cough Collections 1&2) was examined for commonalities between the silence and blip segments. Fortunately , all silence and blip clips were below a certain length and could easily be filtered out automatically. Segments containing human voices can not be automatically identified at this time and must be manually removed. For this reason, manual inspection of the audio segments is still recommended at this time.
Data Augmentation
Data augmentation is the process of artificially expanding a data set by means of transforms. These transforms may take the form of shifting, cropping, scaling or etc. Data augmentation can also change the data set to be more representative of the problem of interest by introducing variations that are not represented in the unaugmented dataset. In this study the cough files are standardized to the same length (frame) to match the input size of the algorithms used but a cough may occur at any point within the frame. By using time shifting augmentation several samples of cough can appear in different regions of the frame. This time shifting within a frame can have the effect of desensitizing an algorithm to a temporal dependency that does not have bearing on if a cough is wet or dry.
Issues with data augmentation
Data augmentation does come with some shortfalls. Each new generated sample is similar to another sample present within the existing data set. As a higher percentage of the data set becomes augmented, the data set will start to exhibit similarities that may not be as pronounced outside of the augmented dataset. This effect is more apparent on very small datasets which may not be an accurate representative subset of the larger problem of interest. E.g Cough samples from a very small set of individuals may exaggerate frequency components that may not be as dominant in the general population. E.g A dataset containing only male coughs. In the context of a machine learning classifier, the prediction accuracy may increase on similar samples but will fail to generalize well on samples that are not as similar to the original samples.
The correct level of data augmentation and application is a current active research topic. For this study, only established methods were employed and augmented data was limited to representing 80% of the entire dataset. As more samples were introduced, the level of augmentation was reduced. Two types of data augmentation were used in this study, time shifting and adding white noise.
Female Dry Cough Raw Audio

Time Shifted Female Dry Cough

Female Dry Cough with additional White Noise

Feature extraction is the process of applying transforms to data to gain insight into the structure of the data, or to find similarities or differences between samples of the data. It can also serve as a method of dimensional reduction or to convert data from one format to another. E.g Audio to image files. The features investigated in this study are shown below.
Mel-frequency cepstrum (MFCC)
The mel-frequency cepstrum (MFCC) is a representation of the short-term power spectrum of a sound, based on a linear cosine transform of a log power spectrum on a nonlinear mel scale of frequency.
Female Dry cough

Female Wet Cough

Male Dry Cough 
Male Wet Cough

Spectrogram
A spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time. Spectrograms are able to capture both frequency and temporal information about a signal.
Female Dry Cough

Female Wet Cough

Male Dry Cough

Male Wet Cough

FFT Squared or FFT Magnitude
FFT Magnitude is a common technique used to drive down the noise floor in the FFT while accenting the main frequency components of the signal.
Female Dry Cough

FFT Magnitude of same Female Dry Cough

Chromagram
The entire spectrum of the audio signal is projected onto 12 bins representing the 12 distinct semitones (or chroma) of the musical octave. The chromagram was included in the librosa library employed in this study and was implemented for no extra effort.
Chromagram of Female Dry Cough

Spectral Contrast
Represents the relative spectral distribution instead of average spectral envelope power.
Spectral Contrast of Female Dry Cough

Tonnetz
Tonnetz or tone-network is a lattice diagram that represents the tones of western music within a space. Tonnetz is useful for analysing the tonal content of an audio sample. While often used for analysing the structure of music, torrentz was investigated in addition to the other features as it detects the changes in the harmonic content of audio signals that may be useful in differentiating wet from dry coughs. Torrentz was included in the librosa library employed in this study and was implemented for no extra effort.
Tonnetz of Female Dry Cough

Data Processing Pipeline
The following diagram shows a high level overview of the flow of data within the software

- Load files into memory as dictionary of numpy arrays
- The dictionary format
- Key = Set Name
- Value = nxm numpy matrix
- N = # of files in set
- M = Samples in each audio file
- The dictionary can be fed into Data Augmentation then into Feature Extraction or directly into the Feature Extraction. The feature extraction block creates a new dictionary containing numpy arrays of the extracted features. The new dictionary is of the same format as the input dictionary.
- Once features of interest have been extracted the data can analyzed.
Preliminary Analysis
Before the time investment could be justified to collect additional samples (Cough Collection 2) a preliminary analysis had to be conducted. The goal of this preliminary analysis was to attempt to differentiate a Wet Cough from a Dry Cough with the samples from Cough Collection 1.
Wet and dry coughs were separated into two sets, one set contains all wet coughs while the second set contains all dry coughs.
The Preliminary Analysis was based upon the following Hypothesis;
To differentiate Wet and Dry Coughs we must be able to prove each set is more similar to itself than to the other sets. I.E. A wet cough is more similar on average to another wet cough than to a dry cough. This implies that the average correlation within a set must be greater than the average correlation between different sets.
Procedure
Before the preliminary analysis could begin, some preprocessing steps had to be accomplished. First, each of the 24 samples in the Cough Collection 1 dataset had to be segmented into Isolated coughs. The isolated coughs were then separated into two different sets. One set contains audio for wet coughs and the other set contains dry coughs. Both sets were inspected for errorunous inclusions including human voices or background noise. The FFT was taken for each cough and stored in a numpy array.
The analysis was conducted in the following fashion:
The average correlation within a set was found by first finding the correlation between each audio file (cough) and all the others within the same set. The average correlation was then computed. i.e. All members of the Wet Cough Set vs All members of the same Wet Cough Set , All members of the Dry Cough Set vs All members of the Dry set.
Then the correlation between each audio file(cough) and all other audio files within the other set was calculated. i.e All members of the Dry Cough Set vs All members of the Wet set.
According to the stated hypothesis a higher average correlation should be observed between audio files(coughs) within the same set than the average correlation between the two sets. I.E The correlation between a dry cough and another dry cough is expected to be greater than the correlation between a dry and wet cough.
After several experiments it became evident that the high noise floor within many of the samples was interfering with the analysis. Differences due to gender also came to the surface. To correct these issue the analysis was amended with the following changes:
To filter out noise in the frequency domain FFT magnitude was computed instead of the FFT.
The files were separated into four sets (FDC,FWC,MDC,MWC) as opposed to the previously declared two sets(WC, DC).
Results

- X = Different Gender O = Same Gender
- Blue = Wet Cough vs Wet Cough or Dry Cough vs Dry Cough
- Red = Wet Cough vs Dry Cough
- Error Bars = Variance within correlations
Correlations
- As expected the highest correlations are within sets e.g FWC vs FWC, MDC vs MDC …
- Lower correlations are seen between files of differing sets, except in the cases where MWC is compared.
- Differing gender set comparisons have a lower correlation on average than same gender sets
Issues:
- MWC seems to have a low self correlation compared to the other sets.This may be due to differences in individuals used for the study, natural variation or misclassification of coughs.
- FDC is the smallest dataset and shows a high variance.
Conclusions:
Weak trend observed indicating that initial hypothesis may be valid.
Gender does appear to have an influence upon the correlations
Dataset exhibits high variance and may be too small exhibit strong trends
Small dataset may allow a few misclassification errors to have a large impact upon the correlation measurement
The MWC set appears to be an outlier set due to its very low autocorrelation as compared to the other sets. This could be explained by differences between individuals used within the set, natural variation, misclassification , or an artifact of the set size.
Second Analysis
Once samples from Cough Collection 2 began coming in, a quick secondary analysis was performed in the same manner as the first analysis except for the application of a 5 Khz low pass filter to each sample. The filter cutoff frequency determination is covered in the further analysis section of this paper.

With the addition of several more coughs into the data set the trend exhibited in the first preliminary analysis appears to be more pronounced but, conclusions will be suspended until more samples can be analyzed.
Further Analysis
To gain a better understanding of features that allow for wet/dry differentiation additional analysis was conducted. This analysis focused on the frequency domain since promising results were seen in the preliminary study. Instead of selecting frequencies arbitrarily, a method was devised to highlight the dominant frequencies within each set.
To visualize the average power intensity within a frequency bin over an entire set, heatmaps were generated. The brightest (hottest) pixels in the heatmap represent the frequencies with the highest power intensity.
Procedure
The procedure to create heat maps is as follows:
All files in every set were normalized to the same average audio level. The FFT of each cough in each set was taken and stored in a numpy array. The numpy array were stacked vertically to produce an (nxm) matrix.
Where:
- n(rows) = # of files within a set.
- m(Columns) = # of frequency bins.
Numpy Array
array([ 2.5585873e-06, -7.2517460e-06, 5.7485468e-06, …,
\-1.5441233e-02, \-2.1383883e-02, \-1.4706750e-02\], dtype=float32)
The average power intensity within the entire set was found by averaging the power in each frequency bin across all the rows(coughs) within the set.
Results




Graphs
- The X axis is the frequency bin number. 0 is the minimum and 16000 Hz is the maximum. There are 256 bins. Each bin represents 62.5 Hz of bandwidth.
- The y axis is a meaningless graphing artifact since the plotting function can only plot “2d” data
- The whiter the pixel, the more average power is present within a frequency bin for a set.
- The graph autoscales the values from 0-255 where 0 is the minimum value and 255 is the maximum value.
Conclusions
- Coughs from all sets do not have much power in the higher frequency bins.
- Dry coughs are more narrow band than wet coughs on average.
- MWC is very spread spectrum as compared to the other sets, which may explain the set’s low autocorrelation.
Developing filters
An analysis was conducted to analyze cough data within a certain frequency range to determine if further separation between wet and dry coughs is possible.
Instead of arbitrarily selecting frequency bins to filter out, frequency bins where the most similarities(AND) and differences(XOR) occurred were determined by the following method:
First a filter mask was generated for each set by the following procedure:
The power in each frequency bin was averaged across an entire set. If the average power in a bin was above a threshold the bin was marked as a 1 in the mask. If the average power of a bin was below a threshold the bin was marked as a 0 in the filter mask. The threshold was selected as the average power across all frequencies and samples within a set. This procedure resulted in 4 set bin masks, one for each set where the sets are defined as MDC,FDC,MWC,and FWC.
To compare similarities between two sets ( similar frequency content i.e bins) The AND of the two sets’ bin masks was taken to create an AND mask. The AND mask is marked as 1 in the bins where both sets have an average power above the selected threshold. This AND mask was applied to both sets before finding the correlation between sets.
The same procedure was employed to generate the XOR Mask except the XOR was found between the two set masks . The XOR mask was marked as 1 in the bins where the sets exhibit differences with respect to the average power above the selected threshold. This XOR mask was applied to both sets before finding the correlation between sets.
AND Filter

XOR filter

Conclusions
The AND and XOR filters did not noticeably increase the separation between the similar sets( WC vs WC …) and differing sets (WC Vs DC)
This experiment as well as the aforementioned heatmaps both showed negligible energy content in the high frequency bins across all sets. This observation lead to a simpler solution, applying only a low pass filter to the sets prior to calculating the correlations. Additional, background research turned up similar observations by other researchers of wet/dry coughs including the high frequency drop off above 4-5Khz as well as the differences in frequency components between wet and dry coughs. Other researchers reached similar conclusions about using a low pass filter to differentiate wet/dry coughs. 2,3
Low Pass Filter
The chart below is a plot of correlations after applying a low pass filter with a cutoff of 5Khz.
Low pass filtered - Cough Collection 1 
Original (No filtering applied) - Cough Collection 1

Conclusions
The lowpass filtered plot appears similar to the original plot but a slightly greater separation on average between similar sets(WC vs WC, DC Vs DC) and differing sets (DC Vs Wc) can be observed.
The correlations between all sets have dropped in the lowpass filtered plot which is to be expected since the low pass filter removed a highly similar group of frequency bins that was inflating the correlations between sets and making differing sets appear more similar.
Machine and Deep Learning models
Machine learning is the study of developing algorithms and models that can perform a specific task without being explicitly programmed, relying on patterns and inference instead. Machine learning algorithms build a mathematical model based upon training data.
Two types of machine learning algorithms were implemented during this study, a k nearest neighbors (KNN) and a convolutional neural network (CNN). A support vector machine (SVM) was also considered but has not been implemented at the time of the writing of this paper.
KNN
An object is classified based upon the weighted class of its k nearest neighbors given some measurement of “distance”. If k = 1, then the object is simply assigned to the class of that single nearest neighbor.
KNN L1 distance.
Procedure
The data set was loaded into memory and the FFT magnitude feature was extracted. The FFT magnitude feature was chosen for its noise suppression properties. The data was then normalized. The L1 Distance between each test sample and each sample in the train dataset was calculated on a per element basis and summed. The labels of the K closest (Smallest L1 Sum) samples were gathered. The test sample was assigned the label that occurs most often within the K nearest neighbors. Various values of K were experimented with to get the best performance.
Results
The KNN employing L1 distance could not predict with reasonable accuracy the label of the test sample. I.E the KNN could not correctly label a new cough as wet or dry. Prediction accuracy was in the range of 30-50%. This implies the KNN is worse than random chance. The KNN was tested with the mnist dataset as well to confirm proper operation.
Conclusions
Other forms of distance measurement may perform better. This experiment should also be rerun with the addition of the low pass filter applied to each cough.
KNN correlation distance
Procedure
Features were extracted and the dataset was normalized in the same fashion as with the L1 distance KNN. The correlation KNN employed a correlation measurement of distance between the training set and the undetermined (test) cough. Just as in the preliminary analysis, a cough should have a higher correlation with members of its own set than to members of other sets. The main difference between the correlation distance KNN and the preliminary study is exactly what is being compared. In the preliminary study, we compared the averaged features across each set to each other set. In the correlation KNN classifier a single cough is compared to all other coughs within the entire dataset. The single cough is then labeled with the mode of the members with the highest correlation to itself.
Results
The KNN was tested with both non gendered labels and gendered labels. E.g WC vs DC and gender dependent sets ie FWC, MWC, MDC, FDC. As with the L1 distance KNN the correlation distance KNN failed to correctly predict the label of the test cough. The prediction accuracy was worst worse than random chance.
Conclusions
The Knn can be modified to better mimic the preliminary study by comparing the test cough to the averaged features of the entire dataset. In addition This experiment should be rerun with the addition of the low pass filter applied to each cough. It could also be that the data is simply too complex for a KNN to properly predict the test cough label.
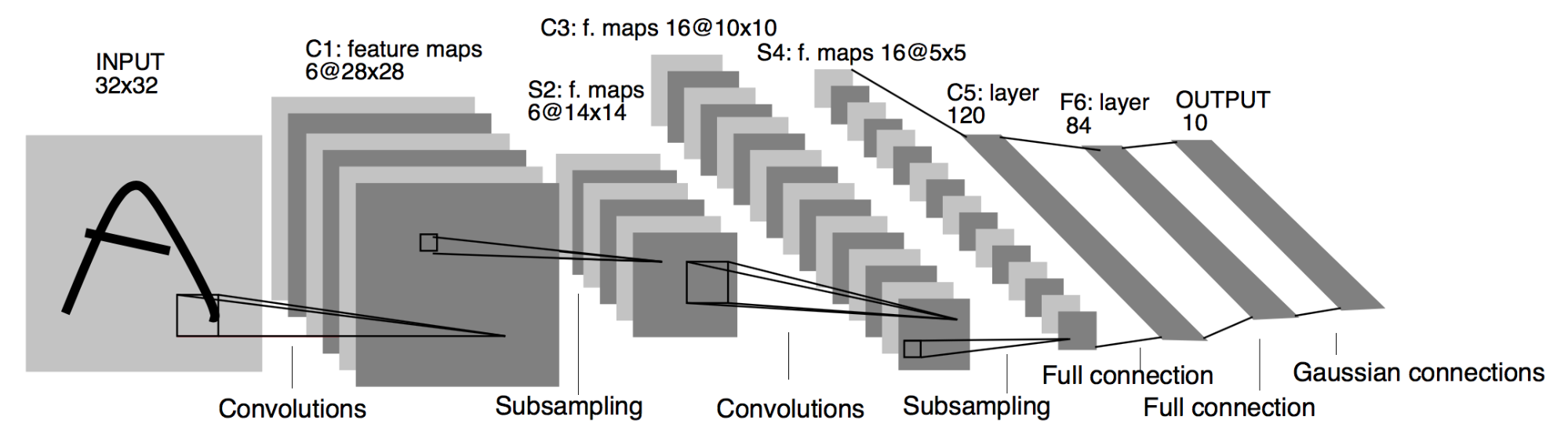
CNN
A convolutional neural network (CNN) consists of an output, input, and a variable number of hidden layers. The hidden layers of a CNN typically consist of convolutional layers, activation functions, pooling layers, fully connected layers and/or normalization layers. CNN have found great success in vision and sound applications.
Training a CNN on data from Cough Collection 1
Procedure
The cough dataset was loaded into memory and padded to make data the same size. Padding is required to match the cough size to the input size of the CNN. The data set was then split into training and test sets. Data augmentation was then applied only to the training set. The FFT magnitude(FFT squared feature) was extracted from both training and test sets. The training and test sets were then normalized independently. The training data was used to train the CNN while the test data was used to validate that the model can correctly classify samples it has not been trained on.
The CNN model used performs well on similar classification tasks. The Cough Collection 1 dataset was split randomly into training and validation sets 5 times to create 5 training and validation data sets. The CNN was trained and validated independently on each of the 5 training and validation sets
Results

- Average prediction accuracy is 56.66 % when evaluated against the test set
- Prediction accuracy (56.66%) is not much better than a random guess (50%)
Conclusions
- Not enough samples for the model to differentiate between Wet and Dry coughs.
- Similar applications use 100’s to 1000’s of samples.
- More samples are needed to properly evaluate the performance of the CNN
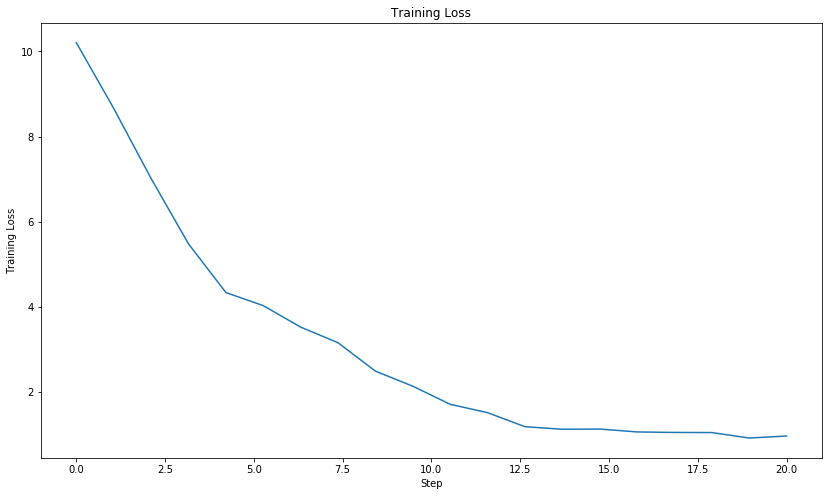
Examining one CNN training run on Cough Collection 1

To gain some insight into why the CNN had failed to label coughs correctly over five experiments, the details of one experiment were examined. The graph below is a comparison of the CNN prediction accuracy between the training data and the test data. The CNN shows improvement in prediction accuracy on the training set as the number of training runs(epochs) increases. This implies the CNN can correctly recognize coughs it has previously seen. Conversely, the CNN does not show any notable improvement on the testing data with increasing training runs. The CNN can not correctly label coughs it has never seen before. A high prediction accuracy on the training set with a low prediction accuracy on the testing set is a consequence of overfitting the training set.
Training on cough collection 1 plus 7 more samples from cough collection 2
Once data from Cough Collection 2 began to come in, the experiment was rerun with all the coughs from Cough Collection 1 and 7 Cough samples from Cough Collection 2. As more training data is provided to the CNN, it is expected that the prediction accuracy on the testing data set will begin to improve with increasing training runs (epochs).


Results
As samples are added the prediction accuracy of the CNN on the testing data is increasing with increasing training runs. This implies that the CNN is starting to learn more generalized features as more cough samples are provided. The accuracy is still very low but, the total number of training samples is very low as compared to similar applications.
Hyper Parameter tuning

Hyper parameters are variables that are not learned during training but can have a large effect upon performance. Hyper parameter tuning is performed by training the CNN with various parameter value combinations and comparing the results between runs. Even with a small number of hyperparameters, the number of possible combinations can become quite large. This precludes manual hyper parameter tuning as a realistic option. Automatic tuning can be done with a framework such as Talos. The CNN was trained on all available samples from Cough Collection 1 & 2. Heavy data augmentation was used to increase the training set size to the same level as used in comparable applications. The augmented data formed about 84% of the training data. Using Talos, 400 CNNs were trained with various hyper parameter combinations. The best performing network parameters were selected from the table generated by Talos. A subset of the hyper parameter table is shown below.
Subset of the hyper parameter search table
| round_epochs |
val_loss |
val_acc |
loss |
acc |
batch_size |
epochs |
| 20 |
1.108661 |
0.778378 |
0.004534 |
1 |
20 |
30 |
| 5 |
1.128583 |
0.783784 |
0.072221 |
0.981439 |
5 |
10 |
| 20 |
0.627663 |
0.848649 |
0.003276 |
1 |
20 |
5 |
| 5 |
1.025006 |
0.783784 |
0.011541 |
1 |
5 |
10 |
|
0.805295 |
0.789189 |
0.339146 |
0.890951 |
5 |
20 |
|
0.932651 |
0.675676 |
1.182459 |
0.577726 |
5 |
30 |
| 2 |
1.619871 |
0.686486 |
0.847847 |
0.825986 |
2 |
20 |
|
2.804706 |
0.681081 |
1.411995 |
0.765661 |
2 |
10 |
|
1.981354 |
0.524324 |
2.683861 |
0.452436 |
2 |
10 |
| 20 |
0.737203 |
0.810811 |
0.002151 |
1 |
20 |
20 |
| 2 |
1.731586 |
0.627027 |
0.920792 |
0.735499 |
2 |
10 |
Conclusions
- It is possible to separate wet and dry coughs into two distinct sets with software
- There are frequency differences between wet and dry coughs.
- Algorithms appear to be improving with the addition of more samples
References
[1] Korpáš, J., Sadloňová, J., & Vrabec, M. (1996). Analysis of the Cough Sound: an Overview. Pulmonary Pharmacology, 9(5-6), 261–268. doi:10.1006/pulp.1996.0034
[2] Rizal, A., Hidayat, R., & Nugroho, H. A. (2015). Signal Domain in Respiratory Sound Analysis: Methods, Application and Future Development. Journal of Computer Science, 11(10), 1005–1016. doi:10.3844/jcssp.2015.1005.1016
[3] Chatrzarrin, H., Arcelus, A., Goubran, R., & Knoefel, F. (2011). Feature extraction for the differentiation of dry and wet cough sounds. 2011 IEEE International Symposium on Medical Measurements and Applications. doi:10.1109/memea.2011.5966670
[4] Ahmad, J., Muhammad, K., & Baik, S. W. (2017). Data augmentation-assisted deep learning of hand-drawn partially colored sketches for visual search. PLOS ONE, 12(8), e0183838. doi:10.1371/journal.pone.0183838
[5] 857389211010878. “KNN (K-Nearest Neighbors) #1.” Towards Data Science, Towards Data Science, 8 Nov. 2018, towardsdatascience.com/knn-k-nearest-neighbors-1-a4707b24bd1d.
[6] Weng, Sheng, and Sheng Weng. “Automating Breast Cancer Detection with Deep Learning.” Insight Data, Insight Data, 13 June 2017, blog.insightdatascience.com/automating-breast-cancer-detection-with-deep-learning-d8b49da17950.