
Computer Architecture
Investigation of Memory Dependence Prediction Strategies with SimpleScalar
Lorenzo Allas, John Grun, Sanandeesh Kamat


0.0 Abstract
A dynamically scheduled processor may default to in-order execution of Load/Store instructions to avoid Memory Order Violations. This is because, loads executed out of order may be dependent upon prior stores, the addresses of which were initially unknown. To overcome the potentially wasted clock cycles of conservatively stalled loads, known as False Dependencies, Memory Dependence Predictor (MDP) schemes have been developed. This paper demonstrates the implementation of two experimental MDP schemes, Store Sets and Counting Dependence Predictor (CDP) within the SimpleScalar framework. In addition, it demonstrates two baseline MDP schemes, No Speculation and Naive Speculation. The conceptual overview, the software implementation details, as well as quantitative simulation results are provided. The performance of these MDP schemes has been evaluated in terms of three metrics: the number of Memory Order Violations, the number of False Dependencies, and the average IPC. Although the results did not indicate a performance enhancement in terms of execution time, they do demonstrate expected behavior in terms of Memory Order Violations and False Dependencies. Possible implementation shortcomings, and future alterations are later proposed.
1.0 Introduction
1.1 The Question: To Issue Load or not to Issue Load?
In a pipelined In-Order execution processor, if an instruction is dependent upon the result of a previously issued instruction then entire processor pipeline must be stalled. This has the effect of drastically reducing the throughput of the processor by, stalling later instructions that have no dependence upon the stalling instruction. To circumvent the performance limitations inherent in the In-Order pipelined processor designs, dynamic scheduling (Out of Order execution) was introduced. Dynamic scheduling works by allowing instructions to issue out of order. Thus if an instruction is issued and is dependent upon the result of a previous instruction, later instructions do not need to wait. Later non-dependent instructions are allowed to issue as long as the processor has available resources (e.g. Adder, Multiplier, FPU, etc.). Inconveniently, the target memory addresses of memory access instructions (i.e. load/store) are not resolved until after issue. Therefore, earlier implementations of dynamic scheduling (e.g.Tomasulo) issued loads and stores in program order to prevent memory order violations. Memory Order Violations occur when loads and store operate on the same memory address in the incorrect order and thus produce incorrect program execution. While this method ensured the correct program execution, the benefits of dynamic scheduling were not realized for load and store instructions. Additionally, any instructions that are dependent have to wait for the Load or store operation to complete even if disperse loads and stores do not operate on the same memory address. In order to maximize performance gains, researchers began experimenting with schemes to allow for out of order execution of loads and stores. In this paper we shall evaluate two such schemes: Store Sets, and Counting Dependency Predictors.
1.2 The Answer: Memory Dependence Prediction Schemes
When issuing a load out of program order, it is assumed that the load does not share an address with (i.e. depend upon) any stores which it has overtaken. Therefore, to issue loads out of program order while target addresses are unavailable, the processor requires Memory Dependence Prediction (MDP). This is very similar to Branch Prediction in that the processor guesses on a decision, detects a mishap, recovers state, and learns to avoid the same mistake on future encounters.
The two baseline (i.e. corner-cases) MPD schemes are No Speculation and Naive Speculation. Under the terms of No Speculation, no ready loads will queue unless there are no non-ready stores behind it. Under the terms of Naive Speculation, loads will queue as soon as they are ready regardless of the number of non-ready loads behind it. Figure 2 illustrates the concepts of these two schemes. No Speculation and Naive Speculation represent the most conservative and the most aggressive MDP schemes, respectively.
Under the terms of the Store Sets algorithms, the processor incrementally logs the PCs of stores upon which loads have historically depended to determine the earliest point in time at which a given load may issue. As conflicting stores are first encountered (detected by Memory Order Violations), their PCs are added to the Store Set to improve future performance. Figure 3 shows illustrates this concept.
Today, distributed systems within which centralized fetch and execution streams are infeasible pose a complication for MDP schemes such as Store Sets. To accommodate distributed systems for which memory dependence predictors do not have global knowledge stores at the full program level, the Counting Dependence Predictor (CDP) scheme predicts the number of stores (not specific PCs) which a load must wait for before it is issued. Moreover, the CDP can default the behavior of a given load to No Speculation (conservative) or Naive Speculation (aggressive) depending on how well it performs at run time. A state machine shown in Figure 4 prescribes the behavior of a given load and is designed to maximize overall performance without requisite maintenance of global store information.
1.3 The Purpose of this Project
The purpose of this project was to extend the SimpleScalar’s sim-outorder simulator to investigate the effectiveness of Store Sets and CDP as MDP schemes. This required familiarization with the SimpleScalar/sim-outorder source code as well as with the selected MDP schemes. Practical feasibility (e.g. memory/power economy) was not a concern of this simulation-driven project, and so the presented implementations represent idealized behavior with unrestricted architectural resources.
2.0 Methods & Materials
2.1 Overview of the SimpleScalar Out-of-Order Simulator
This project utilized the SimpleScalar Toolset to design/evaluate MDP schemes. The SimpleScalar toolset is divided into modules which are applicable to different types/levels of architectural analysis. Because this project was investigating a type of dynamic scheduling, the sim-outorder module was used. Conveniently, the sim-outorder software is solely confined to the file,simoutorder.c. Sim-outorder centers around the Register-Update-Unit(RUU) and Load-Store-Queue (LSQ) which allow instructions to issue/execute out of order but retire in order. Figure 1 illustrates the pipeline of sim-outorder. The RUU and LSQ are themselves simply arrays of the RUU_Station type, which is container for status information of in-flight instructions.
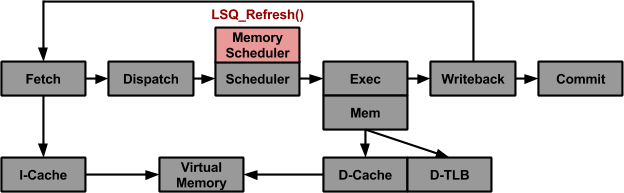
Figure 1: Pipeline for sim-outorder with Memory Dependence Management Highlighted
2.1.1 Memory Dependence Management with Load-Store-Queue Refresh
Memory operations are split into two separate instructions: the addition to compute the effective address and the memory operations itself. The Load-Store-Queue Refresh function (lsq_refresh()), indicated in Figure 1, is an array of RUU_Stations of exclusively loads and stores. It’s functionality is to facilitate memory dependence checking and safe issuing of loads (stores are issued in ruu_issue()). Therefore, lsq_refresh() represented the entry point for most of the software developed for this project. In fact, seach MDP scheme implemented in this project is represented entirely by a variant of lsq_refresh() which is selectively called in it’s stead (See Section 2.3 for details).
By default,lsq_refresh() stalls any ready load if there exists an earlier store with an unresolved address in the LSQ. If however, the address is ready but the operands are not, lsq_refresh() will track the the store’s effective address and stall any ready load only if their addresses match. As will be shown next, this is a relaxed form of No Speculation combined with a rudimentary form of memory dependence checking which Store Sets extends across multiple clock cycles.
2.2 Overview of the Performance Metrics
The three metrics by which an MDP scheme is evaluated are (1) the Number of Memory Violations, the (2) Number of False Dependencies which have occurred during a program’s execution and the average (3) Instructions Per Cycle.
Memory Order Violation program error in which an out-of-order load loads a value before a prior store with a matching effective address completes storing its value to that address. This requires flushing the pipeline and recovering the processor to the state at the point of the offending load.
False Dependency program slow-down in which a ready load is stalled due to the detection of a prior unready store which does not have a matching effective address. This results in wasted clock cycles which reduces program execution speed.
Instructions Per Cycle (IPC) The average number of instructions which are retired per cycle. In multiple-issue processors like SimpleScalar, this can easily rise above 1.
2.3 Implementation of the MDP Schemes and Metrics Acquisition
Implementing the MDP schemes primarily involved altering the actions taken during lsq_refresh(). Specifically, what to do in the event of a detected unready store and ready load. By default, simoutorder does not risk the possibility of Memory Order Violations. Moreover, the functionality to track the number of False Dependencies did not exist. Therefore, this project also involved developing code detect/track the events of Memory Order Violations and False Dependencies, which can be found in check_mem_violation() and countNumFalseDependencies(), respectively.
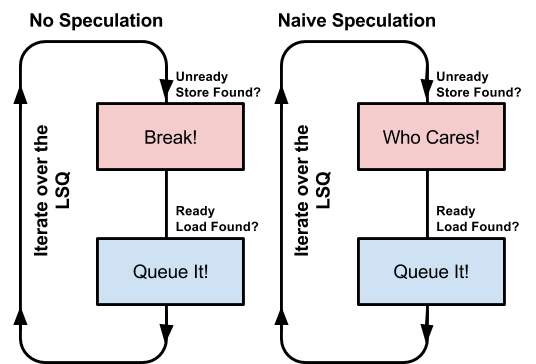
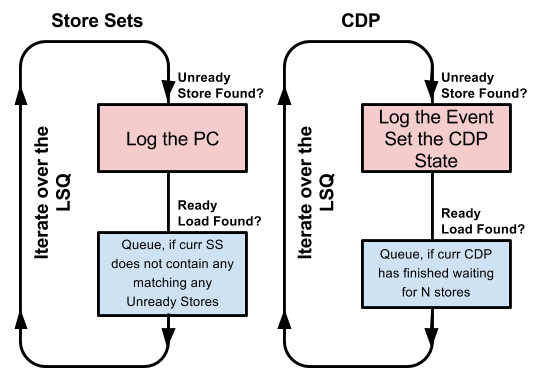
Figure 2 : Logic for Memory Dependence Algorithms
| MDP Scheme | Memory Order Violations | False Dependencies | Project Function Name | CLI |
|---|---|---|---|---|
| Default | None | Many | lsq_refresh() | 0 |
| No Speculation | None | Many | lsq_refresh_NoSpeculation() | 1 |
| Naive Speculation | Many | None | lsq_refresh_NaiveSpeculation() | 2 |
| Store Sets | Few | Few | lsq_refresh_InfStoreSets() | 3 |
| CDP | Few | Few | lsq_refresh_CountingDependencePredictor() | 4 |
Table 1: Expected relative behavior of algorithms
2.3.1 No Speculation (Conservative)
For an algorithm which performs no speculation, the load instructions are dispatched to the memory system only when the addresses of all previous stores are known and the operands of those stores are ready. This configuration successfully avoids memory dependence violations entirely by ensuring memory instructions are issued in program order, but provides no prevention against false memory dependencies (see Table 1). As such, this conservative algorithm served as the baseline memory dependence management scheme against which subsequently implemented prediction schemes were compared for maximum false dependencies.
2.3.2 Naive Speculation (Aggressive)
The naive prediction algorithm assumes no memory dependencies among store/load instructions. All load and store instructions are issued as soon as possible. This configuration is the opposite of no speculation in that no false dependencies occur, but maximum amount of memory violations are incurred. As such, this aggressive algorithm served as the baseline MDP scheme against which subsequently implemented MDP schemes were compared for maximum memory violations. Functionality to flush the pipeline when a memory violation occurs was not implemented in this simulation due to time constraints.
###2.3.3 Infinite Store Sets
The Store Sets algorithm predicts future memory violations based on their previous occurrences. Each load is initialized to behave according to Naive Speculation, in that it assumes it can issue as soon as it is able to. Upon detection of a memory order violation, the conflicted store and load relationship is saved into a table for future reference. This table is known as a Store Set. During a queue refresh, each ready load’s Store Set is searched for a match (i.e. conflict) with any unready store currently behind it. If a conflict is found, the load is stalled until the matching store is no longer on the LSQ. Because no limits are imposed upon (1) the number of stores a load’s store set can contain, or (2) the number of store sets within which a unique store PC can exist, this implementation is considered to be an Infinite Store Set. These limits do exist in practical implementations which were not considered in this project. Figure 2 illustrates the simplified Infinite Store Sets concept implemented in this project. For the project implementation, the Store Set Index is a C struct and the Store Set itself is simply a C array of addresses.
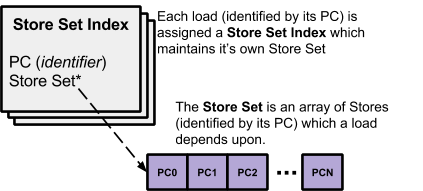
Figure 3: Infinite Store Sets
2.3.4 Counting Dependence Prediction
The counting dependence prediction algorithm uses a state machine for each unique load to determine the correct course of action. Unlike the Store Sets algorithm, the CDP algorithm does not maintain a record of specific Store PCs. Rather, it logs the number of stores which a load must wait for after being ready. This layer of detachment makes CDP an attractive MDP scheme for distributed systems within which globally broadcasted information may not be feasible.Similar to the store set algorithm, each load is initialized to behave according to Naive Speculation (i.e.Aggressive 00 ). As soon as a Memory Order Violation is detected, the state changes to No Speculation (i.e. Conservative.
Figure 4: Counting Dependence Predictor State Machine Diagram
As long as there is determined to be >1 prior stores upon which this load depends (i.e. a Match ), the load will remain Conservative. As soon as there is determined to be 0 or 1 matching stores, the state will change to One-Store and volley between 01 or 11, respectively. If at any time, however, a Memory Order Violation is detected, the load’s CDP state will return to Conservative. Figure 2 illustrates the CDP concept implemented in this project. For the project implementation, CDP Index is a C struct and the CDP state itself is simply a C enum comprising of the four aforementioned states.
2.3.5 Memory Order Violation and False Dependency Detection
Because both Store Sets and CDP are initialized/updated by the event of Memory Order Violations, the project’s check_mem_violation() served three simultaneous purposes.
- Flags Memory Order Violations: issued loads the address of which conflicts with an unexecuted store(s).
- Initializes/Updates the Store Set of the Offending Load
- Initializes/Updates the CDP of the Offending Load
Therefore, although check_mem_violation() is ostensibly merely metric tracker, it also completes the implementation of Store Set and CDP with state feedback The algorithm for Memory Order Violation detection is shown in Figure 5. What allows this algorithm to be effective is that it is called within RUU_Issue() specifically when a ready load is about to be executed. The False Dependency detection function ( countNumFalseDependencies() ), however, is purely a metric tracker and does not alter the state of ongoing Store Sets or CDP state structures. It is called immediately after the LSQ is refreshed. As shown in Figure 5, it simply counts the number of ready loads which come after an unready store. This is a definition of False Dependency which applies closely to No Speculation, but is loosely applicable to the other MDP schemes.
Figure 5: Logic for Memory order Violation Check and False Dependency Check
2.4 Implementation of the Simulations
The following test programs were run using the aforementioned MDP schemes.
| Test Programs |
|---|
| anagram |
| test-args |
| test-dirent |
| test-fmath |
| test-llong |
| test-lswlr |
| test-printf |
Table 2: Test programs used in the experiment
| SimpleScalar Parameter | Val |
|---|---|
| Instruction Fetch Queue Size (in inst/s) | 4 |
| Instruction Decode Width (insts/cycle) | 4 |
| Instruction Issue B/W (insts/cycle) | 4 |
| Instruction Commit B/W (insts/cycle) | 4 |
| Memory Access Bus Width (in bytes) | 8 |
| Register Update Unit Size | 8 |
| Load/Store Queue Size | 4 |
Table 3: Relevant Default Parameters for the Simulations
In order to specify the MDP scheme to run, additional code was written to selectively invoke a different lsq_reshresh_*() depending on the command line arguments as follows:
./sim-outorder - ALGORITHM_TYPE 0 ./tests/bin/* // 0. Default SimpleScalar Behavior
./sim-outorder -ALGORITHM_TYPE 1 ./tests/bin/* // 1. No Speculation
./sim-outorder -ALGORITHM_TYPE 2 ./tests/bin/* // 2. Naive Speculation
./sim-outorder -ALGORITHM_TYPE 3 ./tests/bin/* // 3. Store Sets
./sim-outorder -ALGORITHM_TYPE 4 ./tests/bin/* // 4. Counting Dependence Predictor
By invoking the -redir:sim command line argument simulation outputs were automatically logged to text files. These text files were generated for every combination of test program and MDP scheme, including Default. This resulted in different simulation output text files each of which contain the three principal performance metrics: Number of Memory Violations, Number of False Dependencies, and Average IPC. These results are shown in the next section.
3.0 Results
3.1 Instructions Per Cycle (IPC)
The IPC is most direct measure of overall program performance. According to Figure 6, the various MDP schemes applied to the test data did not result in significant variation in IPC. Because the simulation parameters were fixed solely as described in Table 3, it is possible that these results would have shown greater variance if B/Ws were increased. Nonetheless, there was a consistent decrease in IPC for No Speculation which is by definition the most sluggish of all MDP schemes.
| MDP Scheme \ Program | args | dirent | fmath | llong | lswlr | Math | printf |
|---|---|---|---|---|---|---|---|
| Default | 0.4638 | 0.3924 | 0.7803 | 0.6043 | 0.3613 | 0.9452 | 1.4645 |
| No Spec | 0.4635 | 0.3923 | 0.7778 | 0.6030 | 0.3611 | 0.9410 | 1.4531 |
| Naive Spec | 0.4641 | 0.3924 | 0.7803 | 0.6046 | 0.3613 | 0.9454 | 1.4658 |
| Store Sets | 0.4641 | 0.3924 | 0.7803 | 0.6045 | 0.3613 | 0.9453 | 1.4645 |
| CDP | 0.4610 | 0.3886 | 0.7773 | 0.3701 | 0.3588 | 0.8011 | 0.5214 |
Table 4: Raw IPC Across Test Programs and MDP Schemes
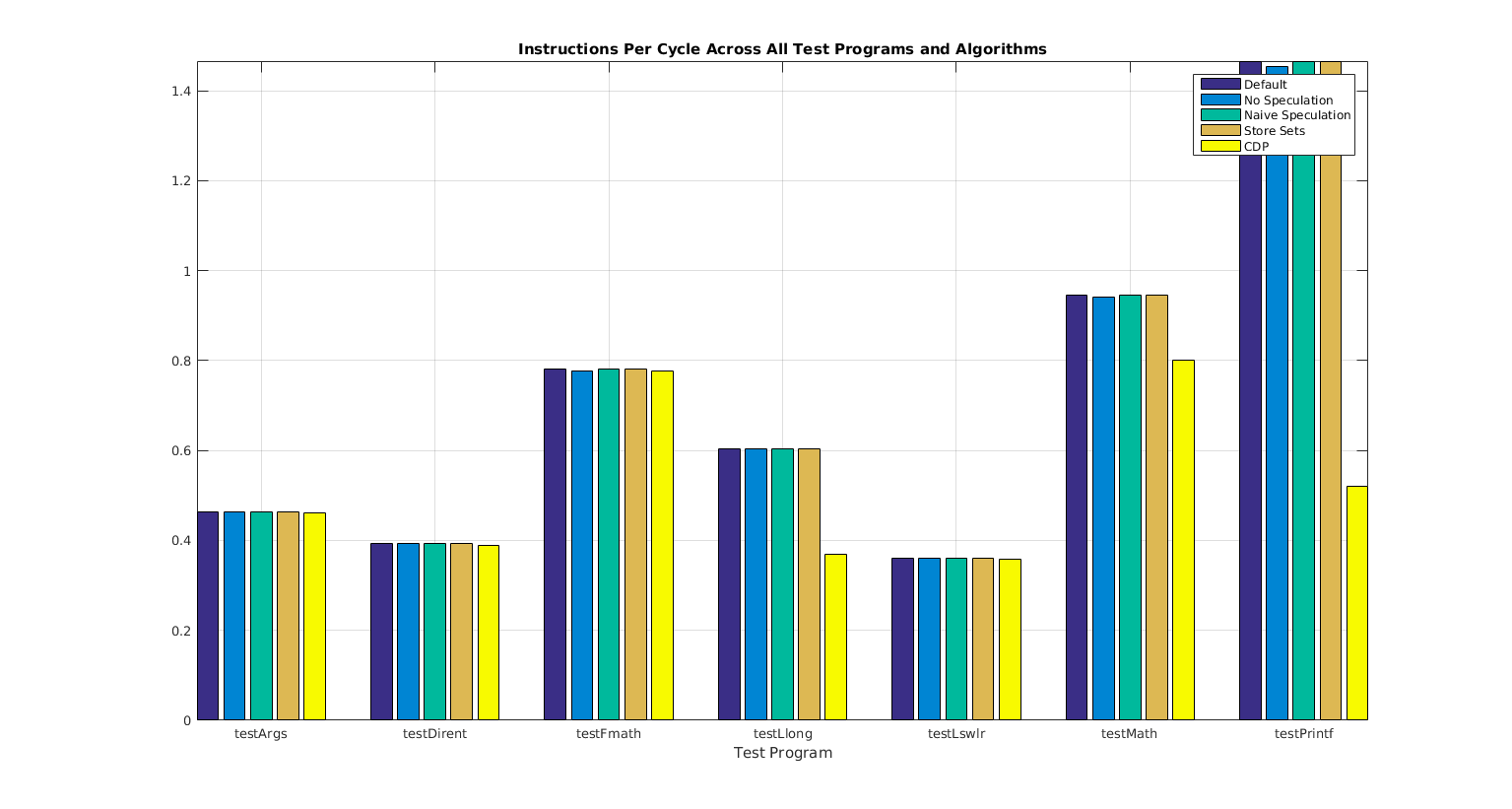
Figure 6: Plotted IPC Across Test Programs and MDP Schemes
3.2 Number of Memory Order Violations
The number of Memory Order Violations generated by the simulations was largely consistent with the initial hypothesis. This is in that the Default, and No Speculation MDP schemes consistently resulted in zero Memory Order Violations. This verifies the project’s implementation of the check_mem_violation() function. By design, the Store Sets and CDP algorithm are intended to incur a few number of Memory Order Violations while affording an enhanced IPC. Because the results of the previous section indicated no IPC enhancements, sadly, we merely have only the predicted Memory Order Violation incursion.
| MDP Scheme \ Program | args | dirent | fmath | llong | lswlr | Math | printf |
|---|---|---|---|---|---|---|---|
| Default | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| No Spec | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Naive Spec | 3 | 0 | 5 | 15 | 0 | 45 | 1745 |
| Store Sets | 3 | 0 | 5 | 6 | 0 | 17 | 26 |
| CDP | 2 | 0 | 4 | 2 | 0 | 8 | 3 |
Table 5 : Memory Violation Count Across Test Programs and MDP Schemes
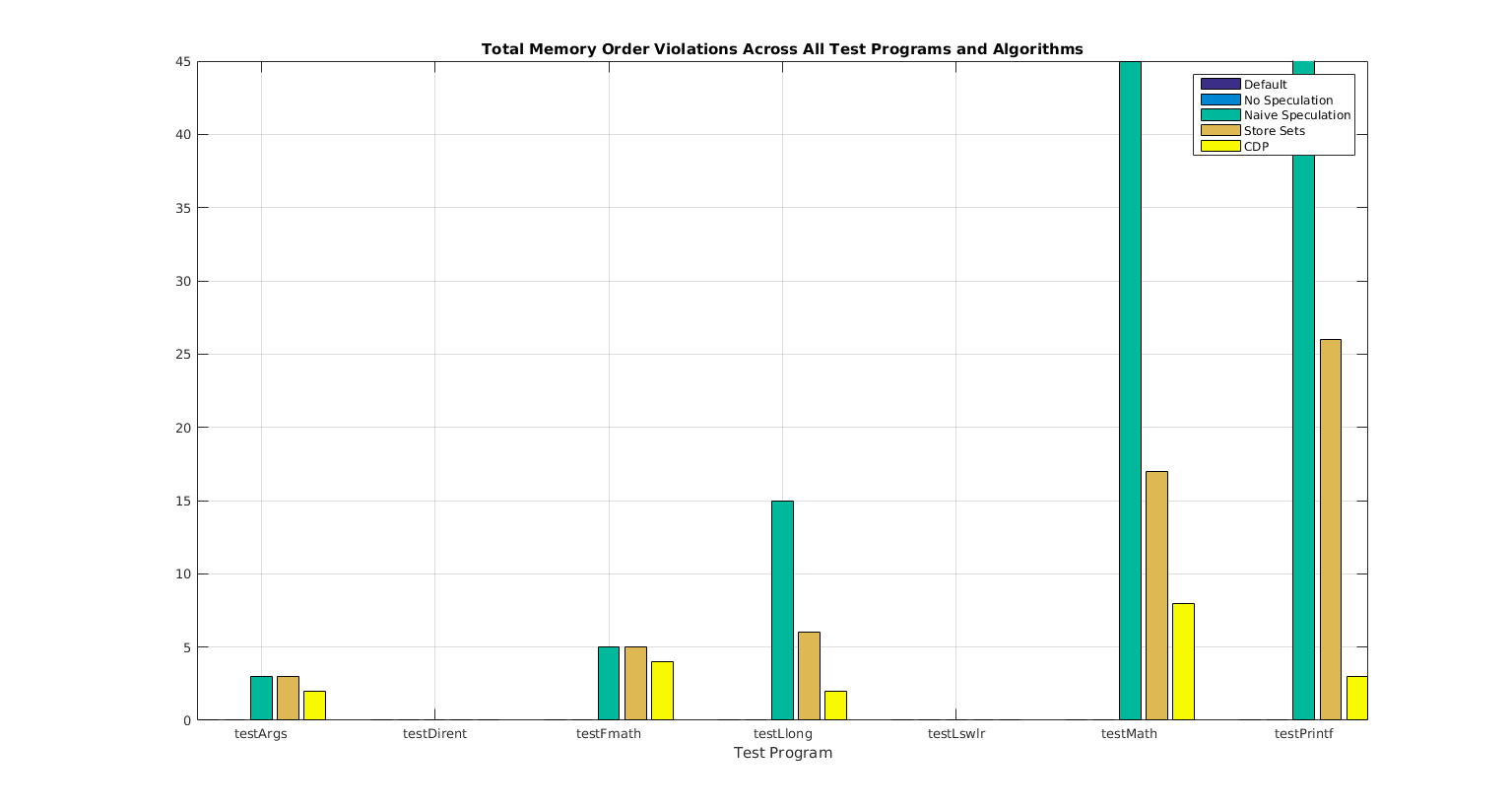
Figure 7: Plotted Memory Violation Count Across Test Programs and MDP Schemes
3.2 Number of False Dependencies
The number of False Dependencies generated by the simulations was also largely consistent with the initial hypothesis. This is in that the Naive Speculation consistently resulted in zero False Dependencies. In addition the No Speculation MDP scheme resulted in the largest number of False Dependencies. This verifies the project’s implementation of the countNumFalseDependencies() function as well as baseline MDP schemes. It is optimistic that the Store Sets and CDP schemes resulted in fewer False Dependencies than the Default and No Speculation. However, as there was no significant improvement in IPC, the overall value of these experimental MDP schemes is still undemonstrated.
| MDP Scheme \ Program | args | dirent | fmath | llong | lswlr | Math | printf |
|---|---|---|---|---|---|---|---|
| Default | 3 | 0 | 88 | 55 | 0 | 158 | 3342 |
| No Spec | 436 | 261 | 1300 | 565 | 351 | 2124 | 35342 |
| Naive Spec | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Store Sets | 0 | 0 | 3 | 17 | 0 | 52 | 3591 |
| CDP | 17 | 24 | 57 | 22 | 27 | 63 | 27 |
Table 6: False Dependency Count Across Test Programs and MDP Schemes
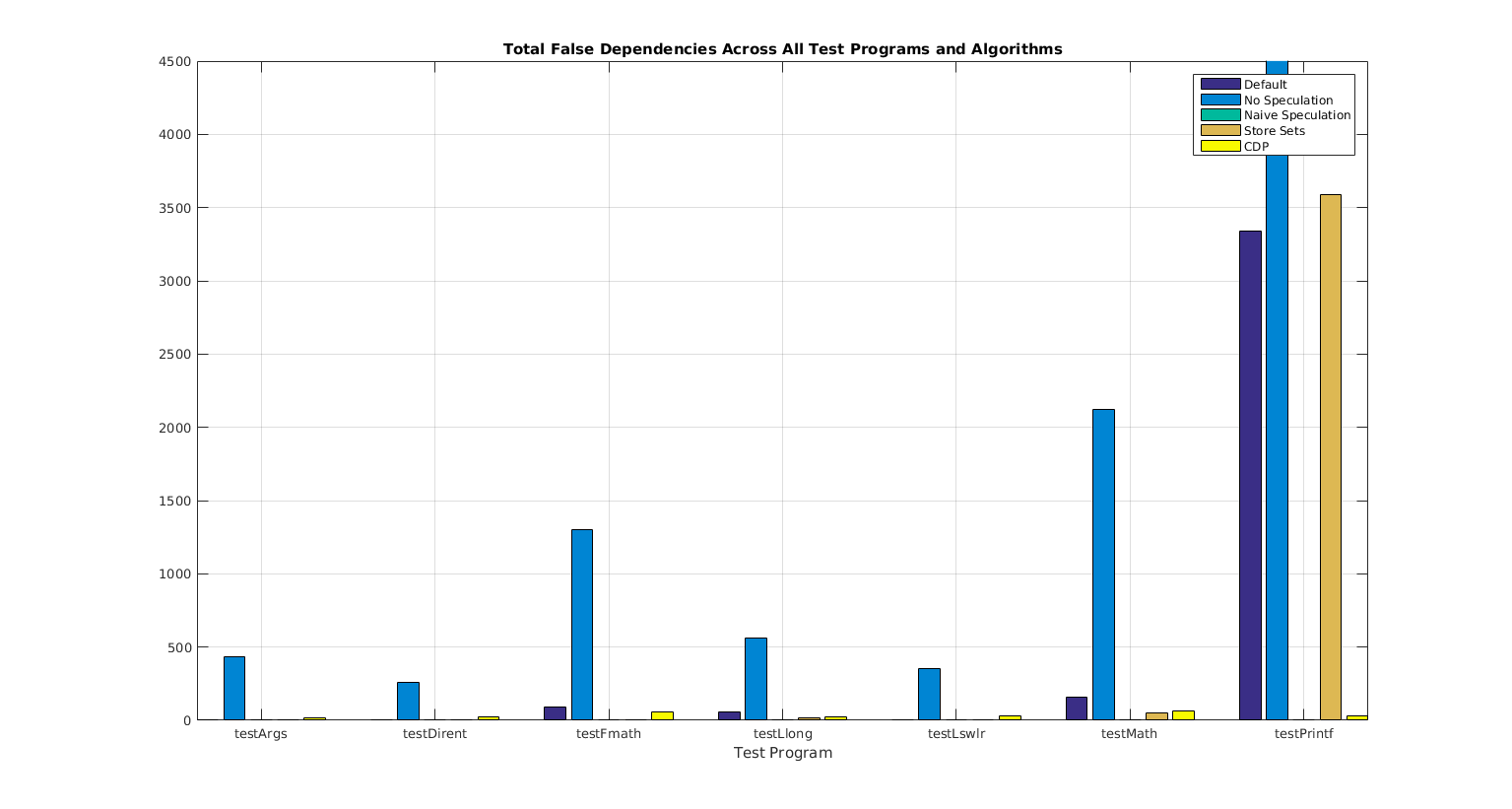
Figure 8: Plotted False Dependency Count Across Test Programs and MDP Schemes
4.0 Discussion
The most significant metric which justifies an algorithm’s utility is the IPC. Because these results did not demonstrate a significant enhancement of IPC for either of the two experimental MDP schemes (Store Sets and CDP), their implementations cannot be proclaimed entirely successful. However, there were several aspects of the results which did support the correctness of their implementations and their consistency with theory. For example:
As expected, the Default and No Speculation MDPs generated no Memory Order Violations and the Naive Speculation MDP many Memory Order Violations. As expected, the Default and No Speculation MDPs generated significant number of False Dependencies and the Naive Speculation MDP generated no False Dependencies. These facts verify the implementations of the baseline MDPs. For the experimental MDPs, as expected, the Store Sets and CDP did generate Memory Order Violations, which is the trigger event by which the Store Sets and CDPs are to be initialized in the first place. Furthermore, as expected, number of False Dependencies generated by Store Sets and CDP are fewer than those of Default, No Speculation, and Naive Speculation.
The various parameters which dictate the width of instructions queueing/decoding/issuing/committing etc. were fixed for all simulations at either 4 or 8 (See Table 3). Because MDP schemes are intended to yield greater dividends for higher bandwidth processors, it is possible that increasing these parameters would reveal inter-MDP scheme variation in IPC. A follow on study in which the parameters of Table 3 are modulated could demonstrate this. Nonetheless there are a few implementation features of Store Sets, CDP, and metric tracking which were either approximated here or entirely foregone.
For example, although the mechanism to detect Memory Order Violations was implemented, the mechanism to recover processor state to the point of the offending load was not. This mechanism would be entirely analogous to that of processor state recovery during branch mis-prediction. The reason no such MDP recovery mechanism existed at first is that the default implementation of SimpleScalar does not allow the possibility of Memory Order Violations at all (See Figure 1). What this should mean is that every Memory Order Violation encountered here caused a programmatic error. However, sim-outorder prints the expected output of each simulated program adjacent to the generated output. Throughout all 40 simulation runs, no differences were seen between the expected and generated outputs. Although the reason for this lack of discrepancy is unknown, it does raise the possibility that SimpleScalar was somehow detecting the Memory Order Violations and recovering processor state. If this is so, the additional clock cycles cost from recovery were already accounted for in the provided results. If not, the implementations provided here are certainly incomplete and represent optimistic IPCs in that the penalty clock cycles of MDP recovery were not accounted for.
One last consideration is that the provided implementations did not strive for minimal memory usage in anyway. For instance, the Store Sets and CDP here maintained a separate index for each load. In practice, much like with branch prediction, the CDP and Store Sets would use reduced table sizes for loads to hash into, and not necessarily track all loads across the entire program execution.
5.0 Conclusion
Because the effective addresses of Loads and Stores cannot always be known at the issue stage, dynamic scheduling processors have traditionally defaulted them to in-order scheduling to avoid Memory Order Violations. To exploit more ILP and reduce False Dependencies, Memory Dependence Prediction (MDP) schemes have been developed. This project sought to demonstrate the performance enhancement capabilities of two such MDP schemes, Store Sets and Counting Dependence Predictor (CDP), within the SimpleScalar simulation framework. SimpleScalar is an industry standard simulator and has been independently verified. Carrying out this project required the team’s thorough familiarization with the MDP scheme concepts as well as the SimpleScalar source code.
The project’s developed source code was peer reviewed by the members of the group and was submitted for further investigation. The project’s developed source code was submitted with built in functionality to toggle between four different MDP schemes (plus Default); two baseline, and two experimental. The two baseline MDPs, No Speculation and Naive Speculation, successfully demonstrated the predicted behavior of maximizing False Dependencies and Memory Order Violations, respectively. Moreover, the Store Sets and CDP implementations demonstrated an expected moderate incurrence of Memory Order Violations and False Dependencies. However, the Store Sets and CDP did not demonstrate a significant enhancement of IPC; one of the primary benchmarks of an MDP scheme’s utility.
Possible explanations for this result include improper input parameter settings detailed in Table 3. Because MDPs are intended for wide-issue processors, it is possible that these particular set of parameters were insufficient to reveal the intended benefits. Moreover, CDP is necessarily a more handicapped version of Store Sets that would only be functionally relevant if SimpleScalar were implemented as a distributed system.
This project enabled the group members to not only learn about but take on Computer Architecture research through the power of modelling & simulation. Carrying out this project allowed us to combine architectural theory with hands-on quantitative performance analysis. Doing so allowed us to act in the capacity of, not only students, but designers.
6.0 References
[1] G. Z. Chrysos and J. S. Emer. Memory dependence prediction using store sets. In Proceedings of the 25th Annual International Symposium on Computer Architecture, ISCA ‘98, pages 142{153, Washington, DC, USA, 1998. IEEE Computer Society
[2] D. Burger, T. M. Austin. The SimpleScalar Tool Set, Version 2.0.
[3]F. Roesner, D. Burger, and S. W. Keckler. Counting dependence predictors. In Proceedings of the 35th Annual International Symposium on Computer Architecture ISCA ‘08, pages 215{226, Washington, DC, USA, 2008. IEEE Computer Society.